

一、背景:虚拟化
虚拟化出现的原因
大多数企业使用的都是物理服务器或者由单家供应商提供的应用,每台服务器又只能运行一个供应商特定的任务
不同供应商之间硬件也并不兼容,如果这时候再各自为他们配备不同的硬件设备必然也会面临物理硬件利用率不足的问题
此时虚拟化技术才得以大展身手,它主要解决了 可对服务器分区 、 可在同一个主机上运行不同环境的应用 两个主要的问题。
虚拟化原理
虚拟化实现技术依托于
Hypervisor(虚拟机监控程序) 。它处于计算机物理层与虚拟机之间,能够有效地管理计算机的物理资源并将这些资源分配给不同虚拟环境。作为服务器,它也可以直接安装在硬件上,直接接管物理资源,可以对资源进行分配,分配给多个虚拟机使用,用户在虚拟机中的指令可以直接通过Hypervisor转发到硬件,直接运行在物理硬件中的
Hypervisor即为Type1,也称为裸机管理程序(Metal Hypervisor),目前市面上常用的VMware ESXi、MiscroSoft Hyper-V和KVM(Kernel-based Virtual Machine)都基于这类Hypervisor
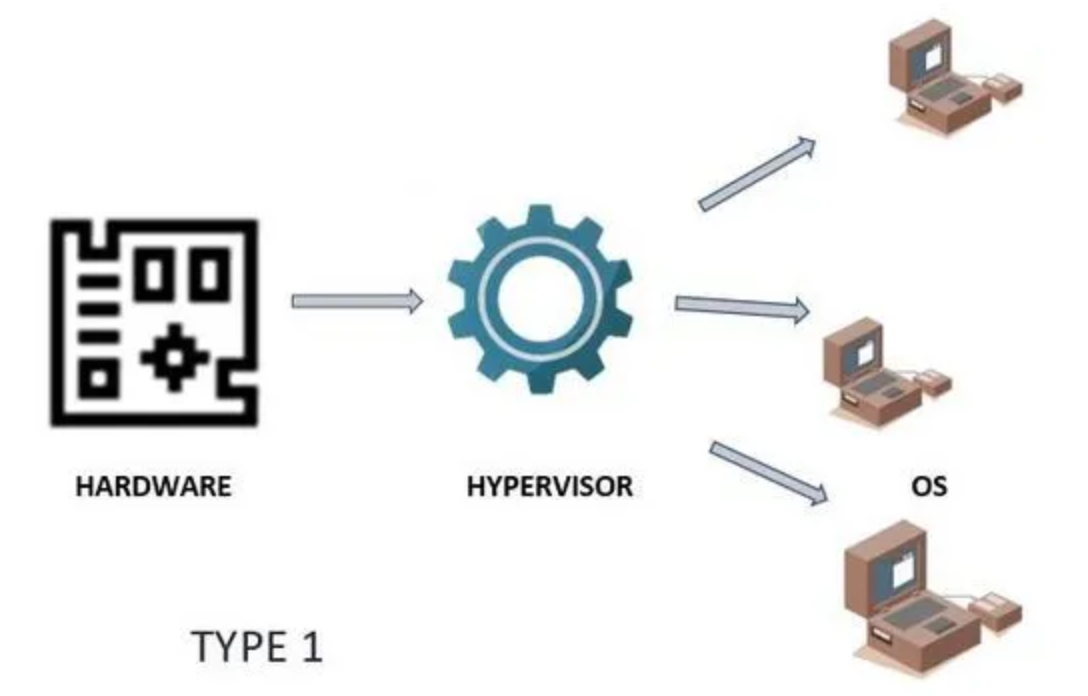
作为软件,
Hypervisor可以直接运行在操作系统之上,即为Type2,使Hypervisor不直接与物理层基础,因此也称作托管程序(Hosted Hypervisor),它主要用于面向个体用户,我们经常在windows中安装的Virtual Box、VMware WorkStation就属于这种类型。此时,相较于Type1,Type2显然多了一些延迟
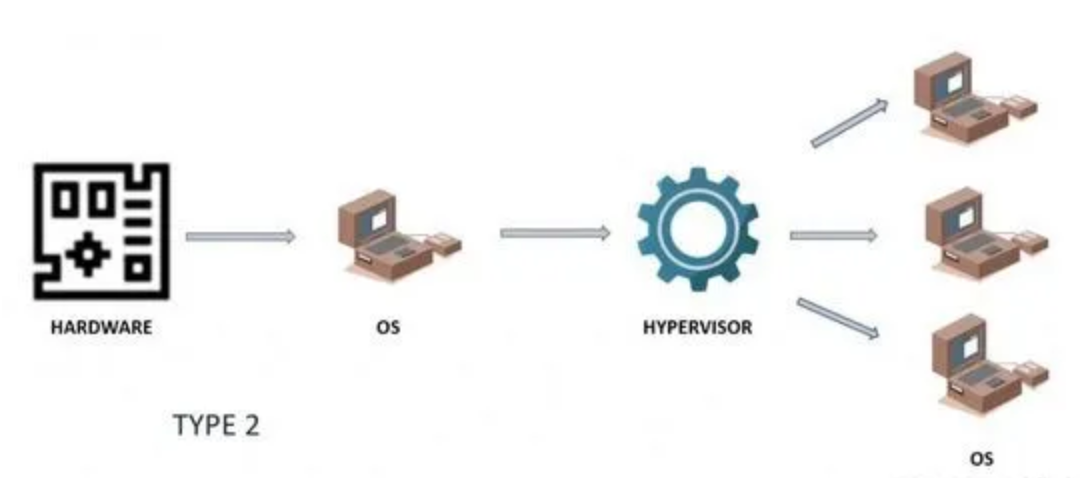
每个虚拟机在
Hypervisor之上相互独立,运行不同的操作系统,操作不同的物理资源,这也带来了我们期望了灵活性和可移植性,我们可以将一个虚拟机从一个Hypervisor中直接迁移到一个新的Hypervisor中,此时就达到了一种 环境复用 的效果
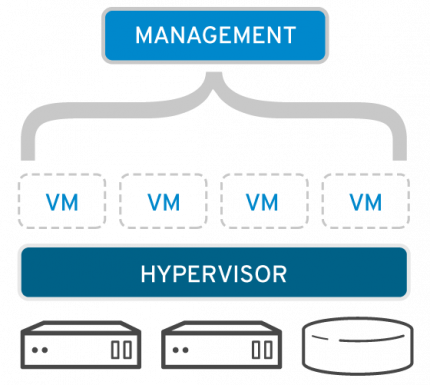
虚拟化缺点
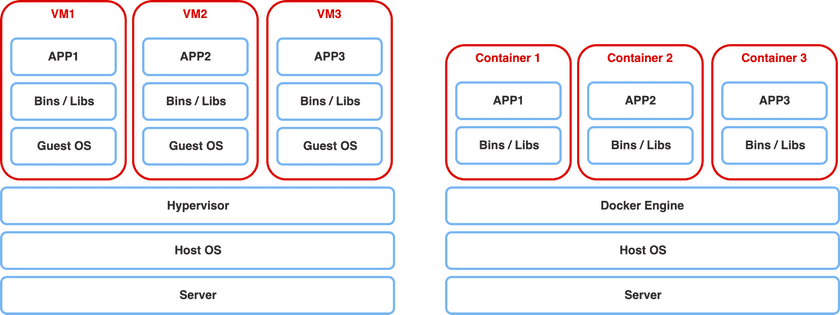
如果希望将自己开发的一个 NodeJs 程序放入虚拟机中,就需要在宿主系统中基于 Hypervisor 安装一个 Linux 虚拟机(单独安装 Linux OS),并在 Linux 中为该服务配置一个完整的 JS 应用运行环境和必要的库,如图所示
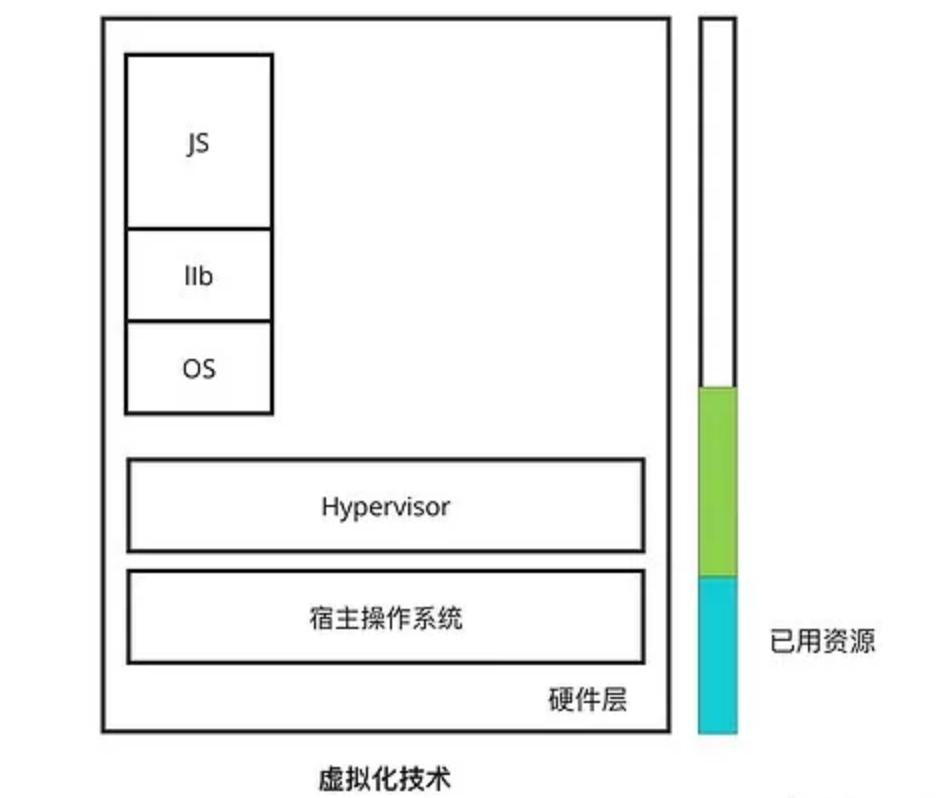
NodeJS 运行时需要的资源可能非常少(10M),而虚拟机本身却占有相当多的资源(>400M),如果继续在该服务器中放入更多的服务,资源消耗程度可见一般,服务器迅速过载
不同的开发环境可能会造成应用程序环境不一致,本地环境一切正常,投入生产环境后却病态百出,不利于 DevOps、持续集成和交付。
二、容器化概念与特点
容器化概念
容器化技术是一种轻量级的虚拟化技术,它让应用程序和其依赖项可以一起打包成一个独立的、可运行的单元,这个单元可以在任何环境中运行,无论这个环境是物理机、虚拟机还是云环境。
容器化技术的核心是利用操作系统级别的特性来实现隔离和限制。在 Linux 系统中,最主要的就是
namespaces和cgroups这两个特性。
容器化特点
轻量:容器化去掉虚拟化中间操作系统层。传统虚拟化技术需要在每个虚拟机中运行完整的操作系统,包括操作系统的内核和所有必要的库文件,容器化通过共享宿主操作系统的内核,无需重复加载多个内核和lib库。容器可以在相同的硬件资源下运行更多的容器实例,从而更加提高硬件资源的利用率,降低运行成本
易于迁移:将应用程序代码和运行所需的相关配置文件,库和依赖项捆绑起来形成一个镜像,这个镜像可以被快速地复制和传输到其他环境中。运行这个镜像,即可重现相同的容器实例,而无需重新配置和安装应用程序
快速启动: 启动传统虚拟机需要启动整个操作系统,包括操作系统的内核、服务和应用程序,因此启动时间相对较长,容器启动只需加载应用程序及其依赖项,无需启动完整的操作系统,因此启动时间非常快速。
三、容器化核心
Namespaces
Cgroups
Namespaces 命名空间
Namespaces 能够在同一台机器上创建多个独立的运行空间,每个空间内的进程只能看到本空间内的资源,看不到其他空间的资源。Linux 系统提供了多种类型的 namespaces,包括 PID(进程)、NET(网络)、IPC(进程间通信)、MNT(文件系统挂载点)、UTS(主机名和域名)和 User(用户)
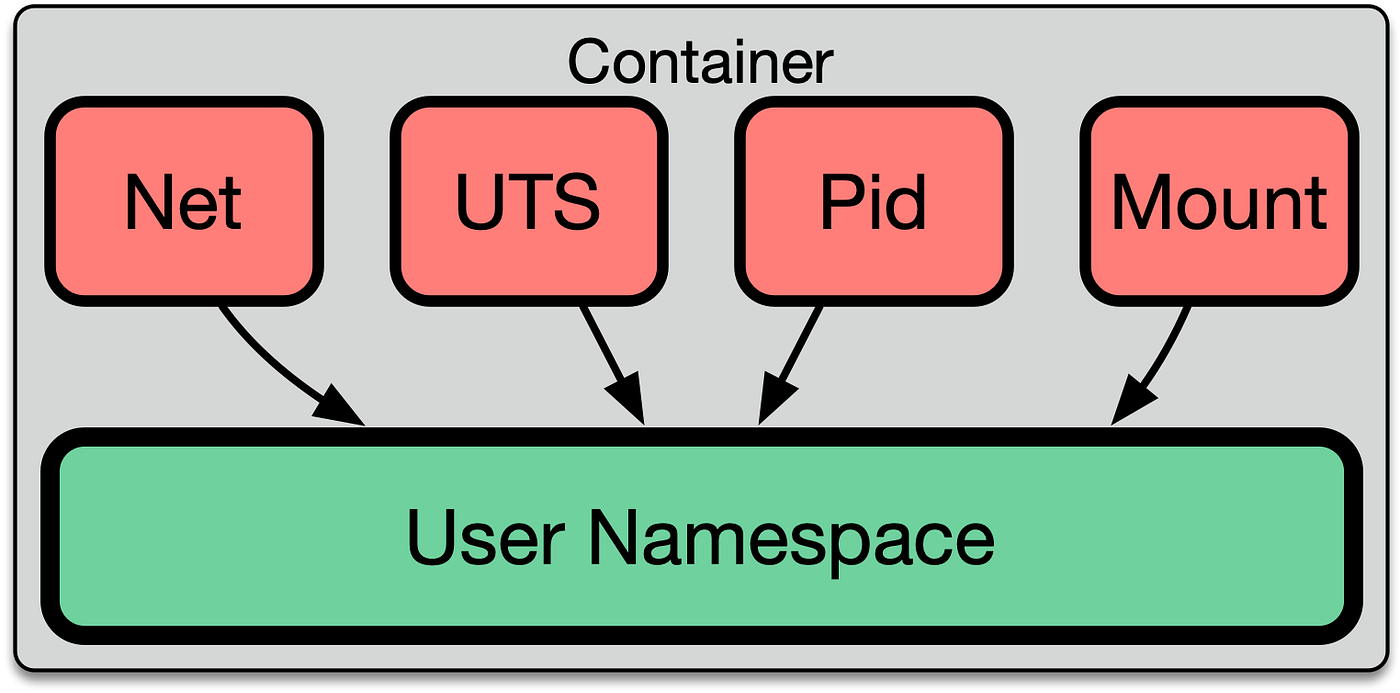
Mount Namespace 挂载命名空间
Mount Namespace:用来隔离文件系统的挂载点,不同
Mount Namespace的进程拥有不同的挂载点,同时也拥有了不同的文件系统视图,不通的Mount Namespace中进程看到的文件系统层次结构是不同的一个进程新建或进入一个 Mount Namespace 后,它的挂载点视图将与其他所有 Namespace 隔离。该进程内部进行的任何挂载或卸载操作都只会影响当前 Namespace,其他 Namespace 的挂载点视图不会受到影响
其他 Namespace 的修改也不会影响当前 Namespace。这种特性使得每个容器可以拥有自己独立的文件系统视图,从而在文件系统层面上隔离容器
PID Namespace 进程命名空间
PID namespace 是 Linux namespace 的一种类型,用于隔离进程 ID 的空间。也就是说,在 PID namespace 中,每个 namespace 都有自己独立的 PID 空间,即在不同的 PID namespace 中,相同的 PID 可能代表着不同的进程
允许每个容器有自己独立的进程空间,而且每个容器都可以有自己的 init 进程(PID 为1的进程)。这就使得容器在行为上更加像一个独立的系统
在一个新的 PID namespace 中启动一个进程时,这个进程和它的所有子进程都会存在于这个新的 PID namespace 中。这个进程在新的 PID namespace 中的 PID 会是 1,而在原来的 PID namespace 中,它的 PID 会是一个新分配的、不同的值
Net Namespace 网络命名空间
用于隔离网络设备、网络协议栈、端口等网络资源。每个NET Namespace都有自己的网络设备、IP地址、路由表、/proc/net目录、端口号等等
可以使容器拥有自己独立的网络环境,每个容器默认都会在自己的NET Namespace中启动,并拥有一个虚拟的以太网接口和一个独立的网络栈
除了以上的隔离,NET Namespace还提供了更灵活的网络配置,例如在每个Namespace中设置不同的防火墙规则,或者在每个Namespace中使用不同的网络服务
IPC Namespace 进程间通信命名空间
用于隔离进程间通信资源的一种Linux命名空间。每个IPC Namespace都有自己独立的System V IPC对象和POSIX消息队列
System V IPC(Inter-Process Communication)是一种旧的进程间通信机制,包括信号量(semaphores)、消息队列(message queues)和共享内存(shared memory)
POSIX消息队列是一种更现代的、基于标准POSIX接口的进程间通信机制
IPC Namespace能够隔离容器中的进程间通信,使得每个容器都有自己独立的IPC资源,而不会与宿主机或其他容器共享。这种隔离性能够增强容器的安全性,并使得容器更像一个独立的系统
IPC Namespace并不会隔离其他类型的进程间通信,例如UNIX域套接字、管道和网络套接字等。这些类型的进程间通信仍然可以跨越IPC Namespace的边界
UTS Namespace Unix分时系统命名空间
Unix Timesharing System Namespace
用于隔离两个系统标识符:主机名(hostname)和网络域名(NIS domain name)
进程在新的 UTS Namespace 中,它可以拥有自己的主机名和网络域名,而这些变化不会影响到其他 UTS Namespace。这样,每个容器可以有自己的主机名,就好像每个容器都是一个独立的网络节点
User Namespace 用户命名空间
用于隔离用户和用户组 ID。每个 User Namespace 都有自己的用户和用户组 ID 空间。在 User Namespace 中,一个用户的 UID 和 GID 可以被映射到外部 Namespace 的不同 UID 和 GID
最主要的用途是将容器的 root 用户映射到宿主机的非 root 用户,从而增强容器的安全性
一个进程可以在 User Namespace 中拥有 root 权限,进行各种需要超级用户权限的操作,但在外部 Namespace 中,这个进程只是一个普通用户,无法影响到宿主系统
User Namespace 也可以让每个容器有自己的用户和用户组配置,这对于运行需要特定用户配置的应用程序非常有用
虽然 User Namespace 提供了用户 ID 的隔离,但并不能防止进程直接访问和修改系统资源,如直接操作系统调用、设备文件等。这些操作的安全性需要通过其他机制(如 seccomp、capabilities、cgroups 等)来保证。
Cgroups 控制组
Cgroups(Control Groups)是 Linux 内核的一种特性,用于限制、记录、隔离进程组(Process Groups)使用的物理资源,如 CPU、内存、磁盘 I/O、网络等。
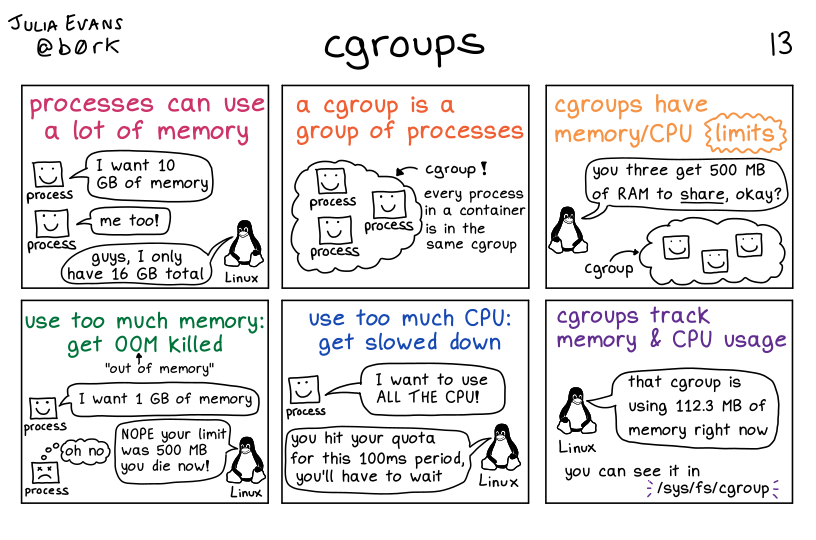
每个进程都会竞争系统资源,这样就会导致一些次要的进程占用了系统的大部分资源,从而影响系统效率,也可能导致资源耗尽的时候引起查杀到主进程,因此linux引入了linux cgroups来控制进程资源,让进程更可控
资源限制:你可以设置某个进程组能使用的最大资源,比如 CPU 使用率、内存使用量等。
优先级调整:你可以改变某个进程组的资源调度优先级。比如,你可以设置让某个进程组优先获取 CPU 时间。
资源统计:Cgroups 可以记录某个进程组的资源使用情况,如 CPU 时间、内存使用量等。
进程隔离:Cgroups 可以将某个进程组的资源使用与系统中的其他进程隔离开来。
控制:Cgroups 可以冻结、恢复进程组中的进程,用于创建检查点和恢复。
Cgroups子系统
cpu:用于限制和管理CPU资源的使用,如CPU时间片、CPU核心数量等
cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告
memory:用于限制和管理内存资源的使用,如进程的内存使用量、内存压缩等
blkio:用于限制和管理块设备I/O资源的使用,如磁盘读写速度、I/O请求队列长度等
cpuset:用于将进程绑定到特定的CPU和内存节点
devices:用于限制和管理设备访问的权限,如阻止进程访问某些设备
freezer:用于暂停和恢复进程的执行
net_cls:用于将网络流量分类和标记,以便对不同类型的流量进行限制和管理
net_prio:用于设置网络流量的优先级
pids:用于限制和管理进程数量
hugetlb:用于管理和分配大页面(Huge Page)
rdma:用于管理和分配RDMA(Remote Direct Memory Access)资源
perf_event:用于对进程的性能事件进行采样和监控
ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace